MDP (Markov Decision Process)
Formal Definition: An MDP is defined by a 4-tuple :
: Set of all states.
: Set of all actions.
: Transition probability, i.e., the probability of reaching state after taking action in state .
: Reward function assigning a scalar reward for state-action pairs.
Markov Property:
The future state depends only on the current state and action:
Objective: Learn a policy that maximizes the expected return: where is the discount factor.
POMDP (Partially Observed MDP)
Formal Definition: A POMDP extends an MDP by including observations and an observation function:
: Observation space.
: Observation model giving the likelihood of observing from state .
Why it matters: In real-world robotics, true states (e.g., positions, velocities) are often hidden. The agent must act based only on observations (e.g., camera frames).
Policy Objective: Learn a policy that maps partial observations to actions.
Imitation Learning (IL)
Concept:
IL focuses on learning behavior by mimicking expert demonstrations.
Avoids the need to hand-design a reward function.
Common use cases: autonomous driving, robotic manipulation, navigation.
Problem Setup:
Expert provides a dataset
Learn to minimize supervised loss:
Behavior Cloning (BC)
Is Behavior Cloning just Supervised Learning?
Yes: Directly fits a function from observations to actions.
No: The i.i.d. assumption breaks down during deployment because action decisions affect future inputs.
Key Pitfall:
Training distribution deployment distribution.
Small prediction errors cause the agent to drift into unseen states (distribution shift).
Theoretical Insight:
If policy makes error per step, expected error after steps can grow to .
See: Ross et al., 2011
🧠 Dataset Aggregation (DAgger)
DAgger = Dataset Aggregation
- Proposed to combat error compounding in BC.
Algorithm:
Collect initial dataset of expert demonstrations.
Train initial policy .
Deploy , record the visited states.
Ask expert for the correct actions at these new states.
Aggregate data, retrain to form .
Repeat.
Pros:
Provably no-regret with enough iterations.
Fixes cascading error issue by training on states visited by the learner.
Cons:
Needs an online expert oracle to label learner states.
Costly in human-in-the-loop settings.
Regret Bound:
🧑🏫 IL with Privileged Teachers
Challenge:
Learning is hard when lacks crucial state info.
[!check] Approach:
Use sim-based privileged policy as teacher.
Student policy learns via supervised learning on teacher rollouts.
Simulation Workflow:
Use full state info in simulation (e.g. positions, object ids).
Train with RL (e.g. PPO).
Render observations , generate labels.
Train student to predict from .
"Simulation lets you generate perfect labels even if you don’t have a human expert."
Applications:
A-RMA: learns locomotion by mapping proprioception to actions via latent adaptation.
Agile But Safe: ray prediction for safe locomotion.
🎲 Deep Imitation Learning with Generative Models
Motivation for Generative Modeling:
Behavior can be multimodal — multiple valid actions for the same state.
Simple supervised learning may average across modes.
Generative models capture this uncertainty.
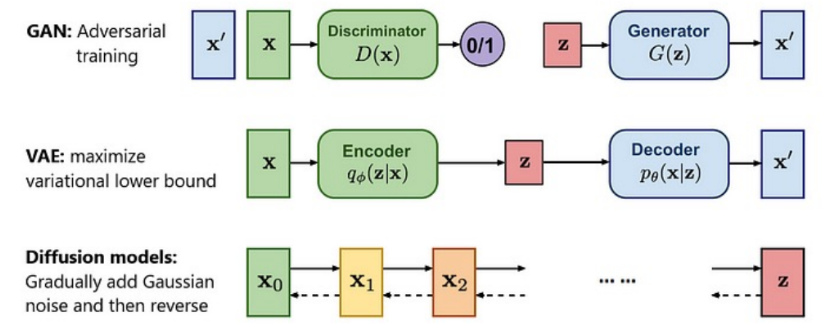
Generative Adversarial Imitation Learning
Discriminator trained to distinguish expert vs learner state-action pairs.
Learner trained to fool using policy gradient.
No reward function required — reward is derived from .
VAE-Based Methods:
Learn a latent variable to represent expert strategy.
Model using conditional VAE.
Use transformer decoders for long-horizon planning.
Diffusion Policy:
Iteratively denoises sampled trajectories conditioned on current observation.
Enables high-resolution multi-step predictions.
State-of-the-art in dexterous manipulation.
Website: diffusion-policy.cs.columbia.edu
Summary Table
| Method | Needs Expert? | Compounding Error? | Key Strength | Key Weakness |
|---|---|---|---|---|
| BC | Yes | ❌ | Simple to implement | Poor generalization |
| DAgger | Yes (interactive) | ✅ | Theoretical guarantees | Needs expert queries |
| Priv. Teacher | Yes | ✅ | Uses full sim state for training | Sim-to-real gap |
| GAIL | Yes | ✅ | No reward needed | Unstable adversarial training |
| VAE + IL | Yes | ✅ | Captures latent intent | Complex training |
| Diffusion IL | Yes | ✅ | Flexible, multimodal modeling | Computationally heavy |
📌 Practical Tips
-
For safety-critical systems, use IL to initialize policies before fine-tuning with RL.
-
In simulation, generate diverse scenarios to improve generalization.
-
Use camera-based augmentation (e.g. domain randomization) to bridge sim-to-real gap.
-
Consider latent or goal-conditioned policies for multi-task setups.
Final Takeaway
Imitation Learning is intuitive and data-efficient, but brittle.
Robust IL requires careful data coverage, model design, and sometimes, generative modeling.
📚 References
-
Ross et al. 2011: DAgger
-
Ho & Ermon 2016: GAIL
-
Chi et al. 2023: Diffusion Policy
-
Lecture: 16-831 Imitation Learning CMU