What does a transformer do?
At a high level, what it does is:
- It takes in a sequence of tokens (words, characters, etc.) and outputs a sequence of tokens.
- It does this by attending to all the tokens in the input sequence and then generating the output sequence.
If you give a model 100 tokens in a sequence, it predicts the next token for each prefix → it’s going to output 100 predictions.
We want a probability distribution over next tokens.
We want to convert a vector to a probability distribution.
- We do this by applying a softmax function to the output of the model.
The output of the model is a vector of size V, where V is the size of the vocabulary.
- Convert text to tokens.
- Map tokens to logits.
- Map logits to probability distribution.
- Using softmax.
Info
Causal Attention Mask: It masks out the future tokens so that the model can’t cheat and look at the future tokens.
Tokens are the inputs to transformers
There are two steps to this process: converting words into numbers and then converting numbers into vectors.
- How do we convert words into numbers?
- We use byte-pair encodings.
- How do we convert numbers into vectors?
- We use embeddings:
- One-hot encoding: Each word is represented by a vector of size V, where V is the size of the vocabulary. In this vector, there is a 1 in the kth position, 0 everywhere else.
- We use embeddings:
Info
We learn a dictionary of vocab of tokens (sub-words). We (approx) losslessly convert language to integers via tokenizing it. We convert integers to vectors via a lookup table.
Note
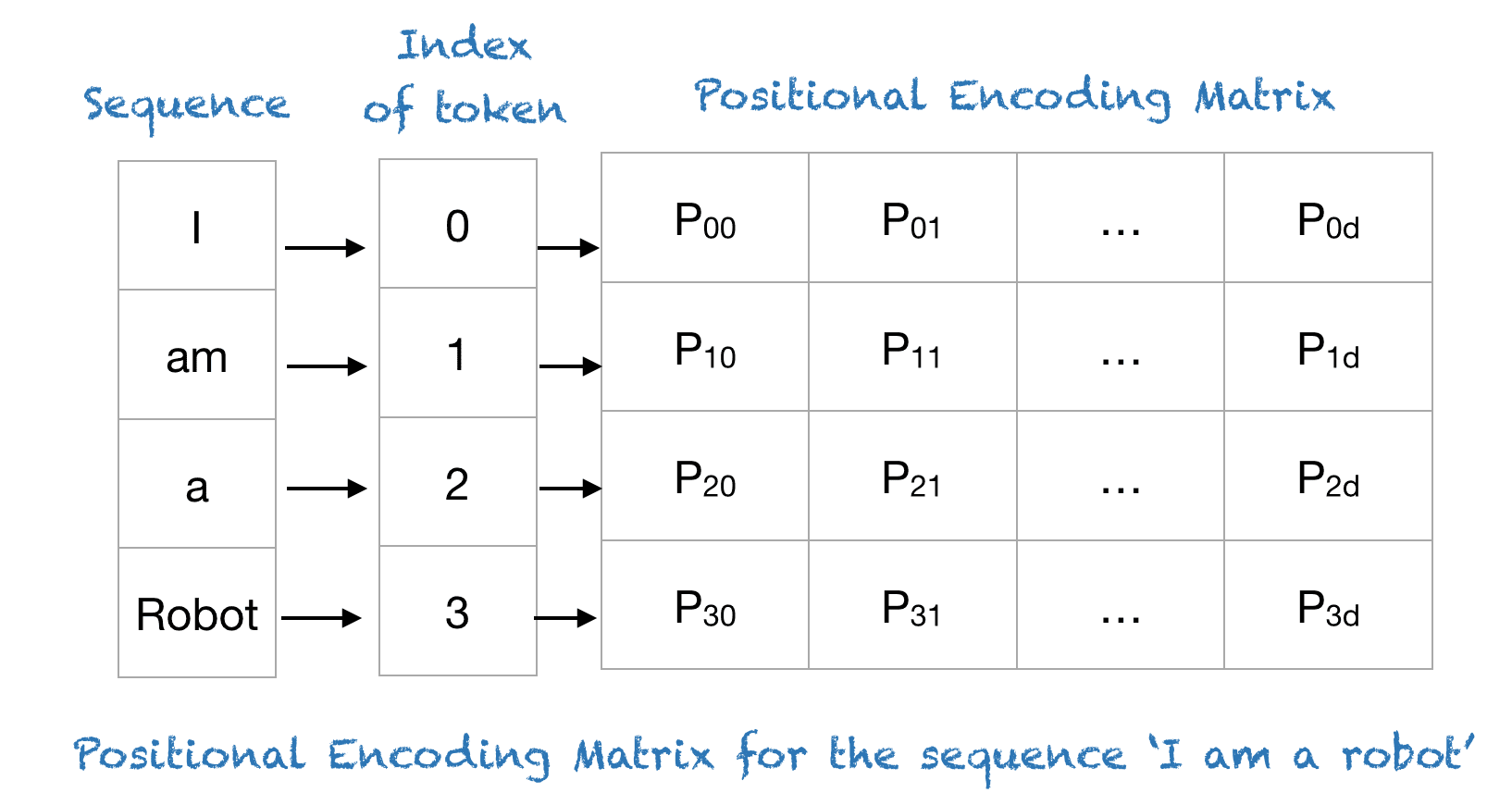
Note: Input to the transformer is a sequence of tokens (i.e., integers), not vectors.
Positional Encoding
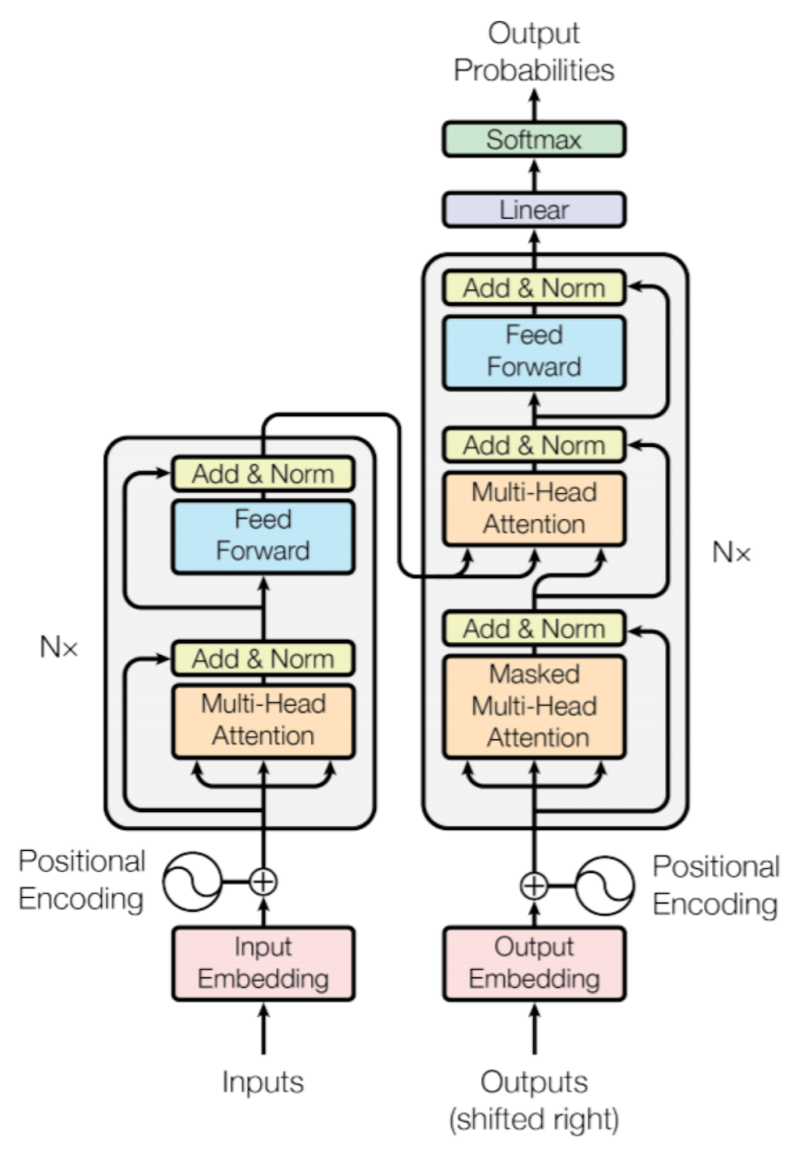
Implementation of a Transformer
High-level architecture of a transformer:
-
Input tokens (integers).
-
Embeddings (lookup table that maps tokens to vectors).
-
Series of n layers of transformer blocks:
- Attention: Moves information from prior positions in the sequence to the current position.
- Do this for every token in parallel using the same parameters.
- Produces an attention pattern for each destination token.
- The attention pattern is a distribution over the source tokens.
- Attention: Moves information from prior positions in the sequence to the current position.
-
Stack of encoders ⇒ Encoding component.
-
Stack of decoders ⇒ Decoding component.
Each Encoder is broken down into two sub-layers:
- Multi-head Self-Attention mechanism.
- Position-wise fully connected feed-forward network.
Each Decoder is broken down into three sub-layers:
- Masked multi-head Self-Attention mechanism.
- Multi-head (encoder-decoder) attention mechanism.
- Position-wise fully connected feed-forward network.
Info
Methods to enhance quality of output:
- Beam Search
Code
class Attention(nn.Module):
def __init__(self, d_model=2,
row_dim=0,
col_dim=1):
super().__init__()
self.W_q = nn.Linear(in_features=d_model, out_features=d_model, bias=False)
self.W_k = nn.Linear(in_features=d_model, out_features=d_model, bias=False)
self.W_v = nn.Linear(in_features=d_model, out_features=d_model, bias=False)
self.row_dim = row_dim
self.col_dim = col_dim
## The only change from SelfAttention and attention is that
## now we expect 3 sets of encodings to be passed in...
def forward(self, encodings_for_q, encodings_for_k, encodings_for_v, mask=None):
## ...and we pass those sets of encodings to the various weight matrices.
q = self.W_q(encodings_for_q)
k = self.W_k(encodings_for_k)
v = self.W_v(encodings_for_v)
sims = torch.matmul(q, k.transpose(dim0=self.row_dim, dim1=self.col_dim))
scaled_sims = sims / torch.tensor(k.size(self.col_dim)**0.5)
if mask is not None:
scaled_sims = scaled_sims.masked_fill(mask=mask, value=-1e9)
attention_percents = F.softmax(scaled_sims, dim=self.col_dim)
attention_scores = torch.matmul(attention_percents, v)
return attention_scores## create matrices of token encodings...
encodings_for_q = torch.tensor([[1.16, 0.23],
[0.57, 1.36],
[4.41, -2.16]])
encodings_for_k = torch.tensor([[1.16, 0.23],
[0.57, 1.36],
[4.41, -2.16]])
encodings_for_v = torch.tensor([[1.16, 0.23],
[0.57, 1.36],
[4.41, -2.16]])
## set the seed for the random number generator
torch.manual_seed(42)
## create an attention object
attention = Attention(d_model=2,
row_dim=0,
col_dim=1)
## calculate encoder-decoder attention
attention(encodings_for_q, encodings_for_k, encodings_for_v)class MultiHeadAttention(nn.Module):
def __init__(self,
d_model=2,
row_dim=0,
col_dim=1,
num_heads=1):
super().__init__()
## create a bunch of attention heads
self.heads = nn.ModuleList(
[Attention(d_model, row_dim, col_dim)
for _ in range(num_heads)]
)
self.col_dim = col_dim
def forward(self,
encodings_for_q,
encodings_for_k,
encodings_for_v):
## run the data through all of the attention heads
return torch.cat([head(encodings_for_q,
encodings_for_k,
encodings_for_v)
for head in self.heads], dim=self.col_dim)## set the seed for the random number generator
torch.manual_seed(42)
## create an attention object
multiHeadAttention = MultiHeadAttention(d_model=2,
row_dim=0,
col_dim=1,
num_heads=2)
## calculate encoder-decoder attention
multiHeadAttention(encodings_for_q, encodings_for_k, encodings_for_v)