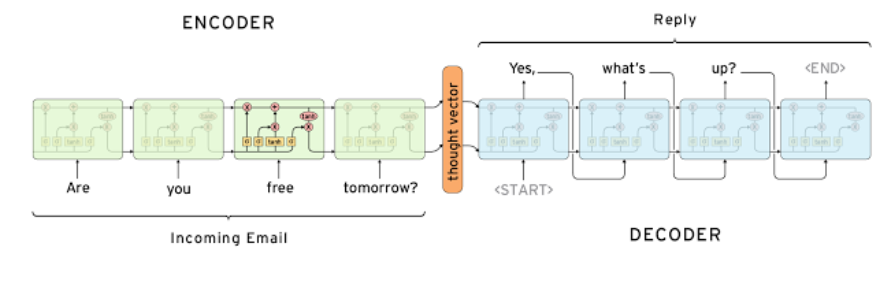
Info
- Consists of two RNN models (an encoder and decoder)
- Encoder learns contextual information from input words and then hands over the knowledge to the decoder side through a “context/thought vector”.
- Decoder then consumes the context vector and generates thoughtful responses
Key Components
1. Encoder
- The Encoder processes the input sequence .
- It encodes the sequence into a fixed-length context vector (also called the latent vector or hidden state), which summarizes the input sequence.
2. Decoder
- The Decoder takes the context vector from the Encoder and generates the output sequence one step at a time.
- It predicts the next token based on the current hidden state, the context vector, and the previously generated tokens.
How Seq2Seq Works
Step 1: Encoding
- The input sequence is passed through the Encoder (e.g., LSTM, GRU).
- At each time step , the Encoder updates its hidden state based on the current input and the previous hidden state :
- The final hidden state and optionally the cell state are passed to the Decoder.
Step 2: Decoding
-
The Decoder uses the context vector (final hidden state of the Encoder) as its initial hidden state.
-
At each time step , the Decoder predicts the next token based on:
- The previous hidden state ,
- The previously generated token ,
- And optionally the context vector.
-
The prediction at each step is given by:
-
The predicted token is fed back into the Decoder for the next time step (autoregressive modeling).
Key Concepts
1. Context Vector
- The fixed-length vector (final hidden state of the Encoder) summarizes the entire input sequence.
- Acts as the “memory” that the Decoder uses to generate the output sequence.
2. Teacher Forcing
- During training, the Decoder is provided with the true previous token from the target sequence as input rather than its own prediction.
- Helps stabilize training but creates differences between training and inference