Motivation
Instead training robots to learn how to do a specific tasks by collecting tons of specific data (much like basic ML tasks from 10 years ago), we can follow the trend of foundation models and collect tons of different data with different skills, robots, etc and try to get these robots to generalize!
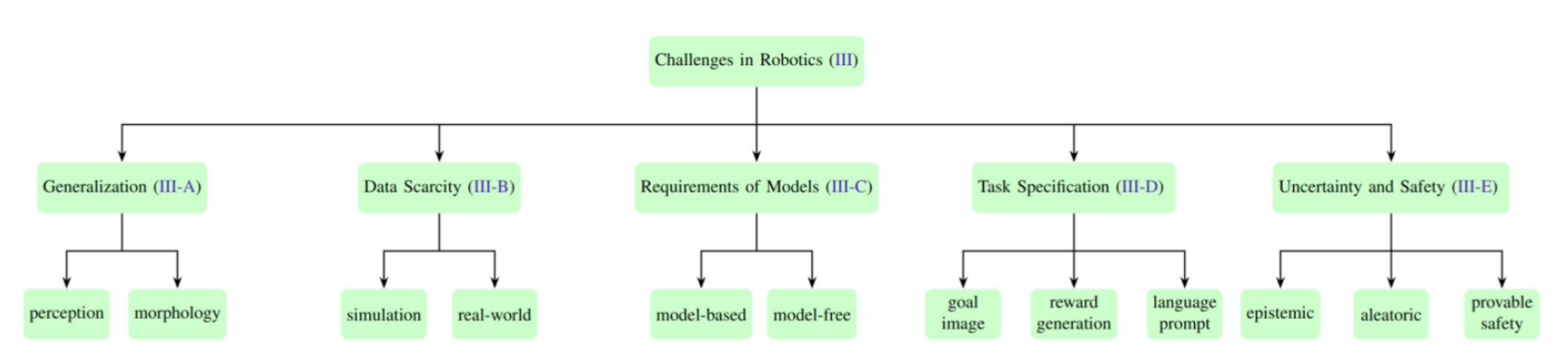
Challenges in Robotics
- Poor Generalization: Current robot algorithms are pretty bad at generalizing to new robotic hardware, environments; hyperparameters and algorithms are usually hand-crafted for a specific task or environment
- Data Scarcity: Data is essential for deep learning-based methods, but the huge range of tasks and environments makes it hard to create large-scale datasets. Simulation is one of the leading ways to help solve this, where synthetic data and techniques like domain randomization, help improve generalization and faster training.
- Task specification: It is hard for users to exactly specify the task, we want robots to understand things semantically.
- Uncertainty and safety: Inherent uncertainty in the environments and task specifications
Foundation Models used in Robotics
The most apparent application is for object recognition and scene understanding, extracting semantic information from the VLM and spatial information from objects/scenes that the robots interact with. Another application is for state estimation and localization, using CLIP and GPT to detect objects and generate labels, helping with SLAM.
Task planning and action generation is another obvious direction. For example, SayCan, uses LLMs… Reward Generation: Language to Rewards for Robotic Skill Synthesis
RT-2: A vision-language-action (VLA) models
generalist policy
- Takes internet-scale pre-training data + Open X-embodiment dataset + collected task data, and combines that with a pre-trained VLM (PaliGemma), with another flow-matching model (action expert), to produce continuous actions.
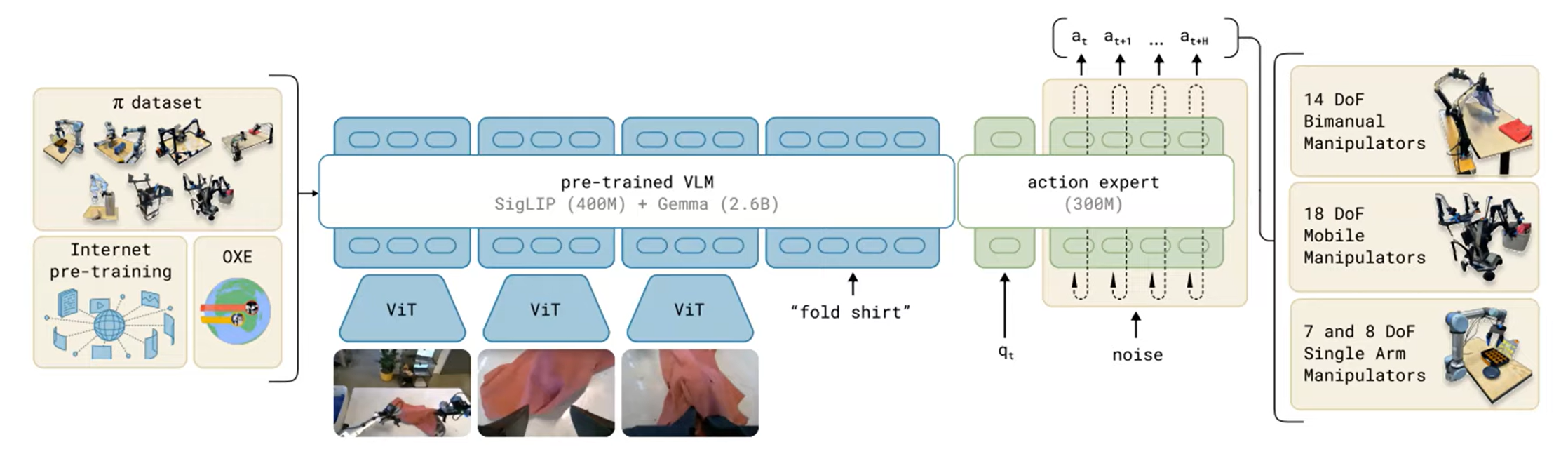
- Model can then be fine-tuned on downstream tasks
Sequential Reasoning for VLAs
- VLA with Embodied Chain-Of-Thought
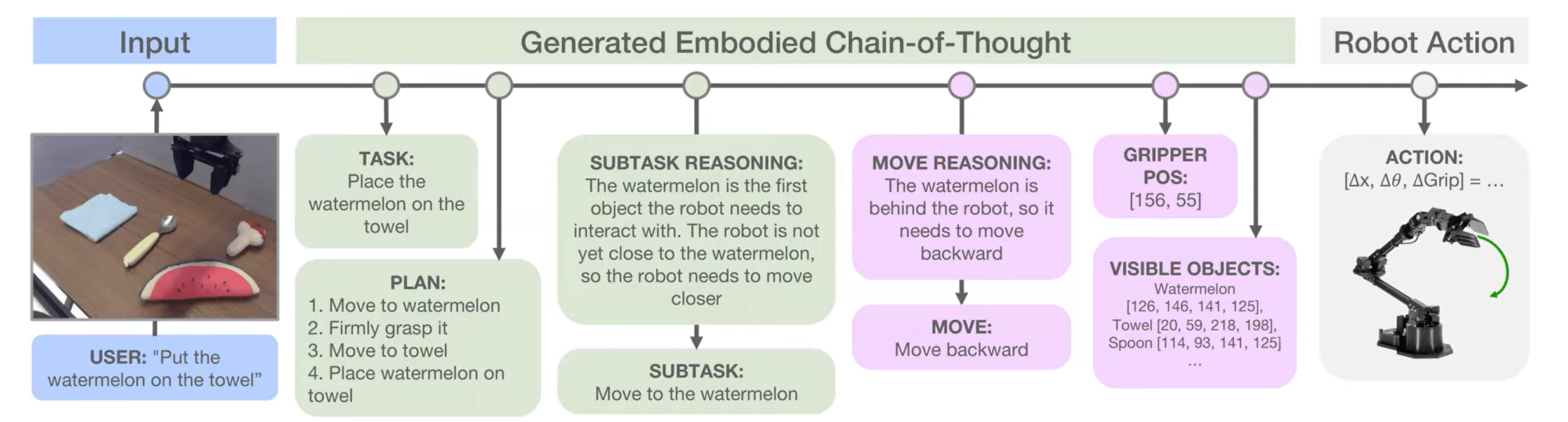
Robotic Foundation Models
Offline RL most methods trained a visual policy in the simulation then transferred the model to real world
Other Interesting Directions
- Improving Simulations and Sim2Real
- LLM for Reward Design with Eureka
- Doing imitation learning
- No simulator. Collect data from real → learn a model → design a policy → deploy
- Meta-learned dynamics model + online adaptive control