Summary
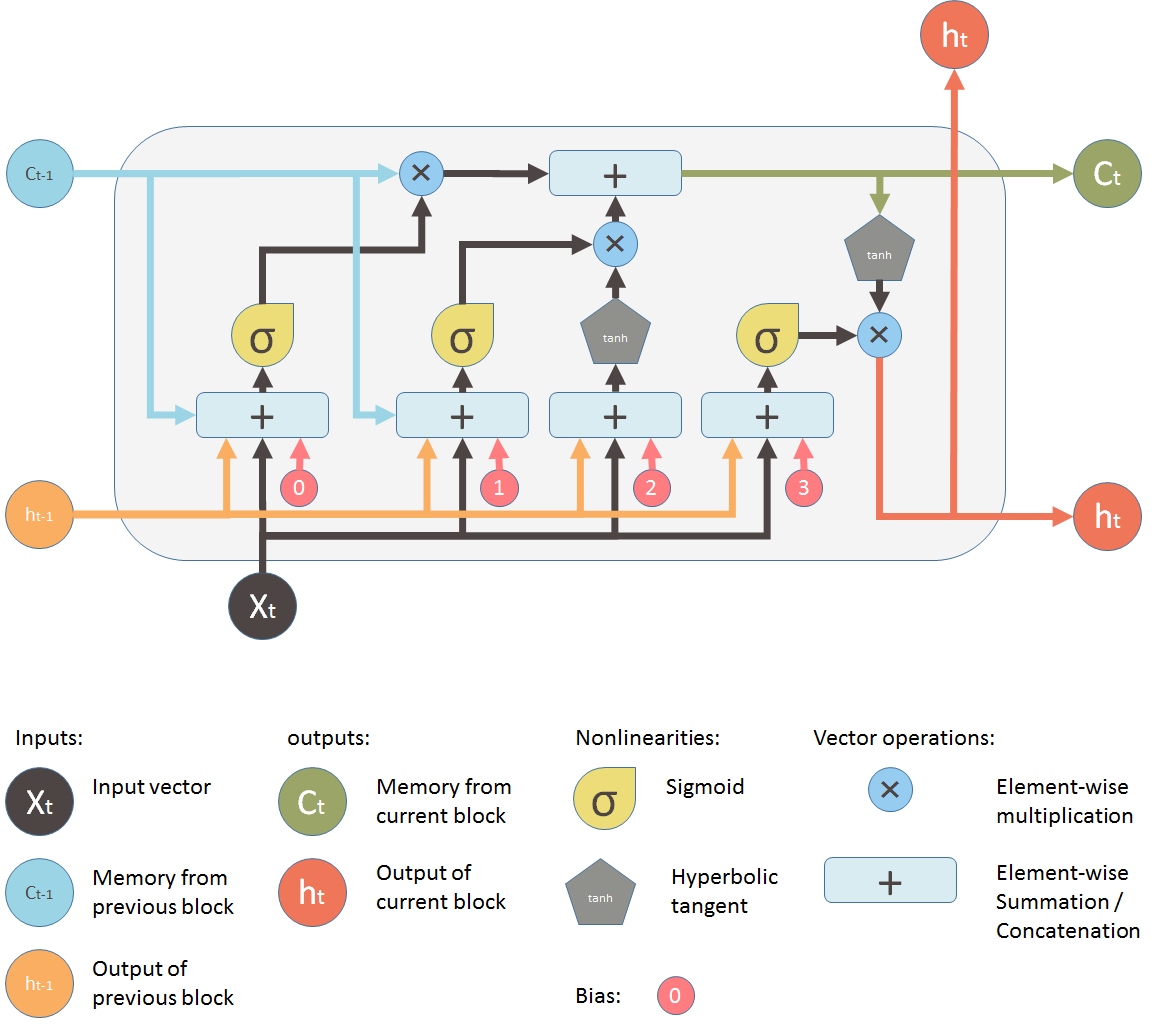
LSTM (Long Short-Term Memory) is a type of RNN designed to overcome the vanishing gradient problem and remember information over longer sequences.
- Input vector : the data point at the current time step (e.g., a word embedding)
- Hidden state : the output at time , passed to the next time step and possibly the next layer
- Cell state : internal memory that carries forward important information through time
The LSTM uses gates to control information flow — allowing it to selectively “remember” or “forget” things.
Gates in an LSTM Cell
At each time step , the LSTM processes:
- the current input
- the previous hidden state
- the previous cell state
Forget Gate
What does it do?
The forget gate decides what information to erase from the previous cell state.
- Outputs values in
- 0 = forget completely, 1 = retain fully
Input Gate
What does it do?
The input gate decides what new information should be stored in the memory cell.
Compute the candidate memory values:
Update the Cell State
Update the internal memory:
- Forget some of the past
- Add some of the new
📤 Output Gate
What does it do?
The output gate decides what part of the memory to pass forward as the hidden state.
Final hidden state output:
PyTorch Implementation
import torch
import torch.nn as nn
class CustomLSTMCell(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# Combine all gates into one matrix for efficiency:
# [forget_gate | input_gate | candidate_memory | output_gate]
self.linear = nn.Linear(input_size + hidden_size, 4 * hidden_size)
def forward(self, x_t, h_prev, C_prev):
# Concatenate previous hidden state and current input
combined = torch.cat((h_prev, x_t), dim=1) # shape: [batch_size, input_size + hidden_size]
# Apply linear transformation to get all gate pre-activations
gates = self.linear(combined) # shape: [batch_size, 4 * hidden_size]
f_t, i_t, g_t, o_t = torch.chunk(gates, chunks=4, dim=1)
# Apply activations
f_t = torch.sigmoid(f_t) # forget gate
i_t = torch.sigmoid(i_t) # input gate
g_t = torch.tanh(g_t) # candidate memory
o_t = torch.sigmoid(o_t) # output gate
# Update cell state
C_t = f_t * C_prev + i_t * g_t
# Compute new hidden state
h_t = o_t * torch.tanh(C_t)
return h_t, C_t
class CustomLSTM(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.cell = CustomLSTMCell(input_size, hidden_size)
def forward(self, x):
# x: shape [seq_len, batch_size, input_size]
seq_len, batch_size, input_size = x.size()
h_t = torch.zeros(batch_size, self.cell.hidden_size)
C_t = torch.zeros(batch_size, self.cell.hidden_size)
outputs = []
for t in range(seq_len):
x_t = x[t]
h_t, C_t = self.cell(x_t, h_t, C_t)
outputs.append(h_t)
return torch.stack(outputs) # shape: [seq_len, batch_size, hidden_size]