MDP (Markov Decision process)
Definitions:
- : State space, : state at time
- : Action space, : action at time
- : Transition probability,
- : Reward function,
Goal: Learn a policy .
POMDP (Partially Observed MDP)
Additional Definitions:
- : Observation space, : observation at time
- : Observation model,
Goal: Learn a policy .
Imitation Learning
Idea
- collect expert data (observation/state and action pairs)
- Train a function to map observations/states to actions
Dataset Aggregation (DAgger)
-
Process:
- Start with expert demonstrations.
- Train policy via supervised learning.
- Run , query the expert to correct mistakes, and collect new data.
- Aggregate new and old data, retrain to create .
- Repeat the process iteratively.
-
Advantages:
- Reduces cascading errors.
- Provides theoretical regret guarantees.
-
Limitations:
- Requires frequent expert queries.
IL with Privileged Teachers
- It can be hard to directly learn the policy especially if is high-dimensional
Obtain a "privileged" teacher
- contains “ground truth” information that is not available to the “students”
- Then use to generate demonstrations for
Example
- Stage 1: learn a “privileged agent” from expert
- It knows ground truth state (traffic light, other vehicles’ pos/vel, etc)
- Stage 2: a sensorimotor student learns from this trained privileged agent
This is especially useful in simulation, because we know every variable’s value in sim. So the privileged teacher learns from that, but the student only learns from stuff it can directly see/measure.
- privileged teacher is usually trained by PPO
Variants
- Student learning in the latent space: Adapting Rapid Motor Adaptation for Bipedal Robots
- Student learning to predict rays: [2401.17583] Agile But Safe: Learning Collision-Free High-Speed Legged Locomotion
Deep Imitation Learning with Generative Modeling
What is the problem posed by generative modeling?
- Learn: learn a distribution that matches
- Sample: Generate novel data so that
For robotics, we want our to be from experts.
There are three leading approaches:
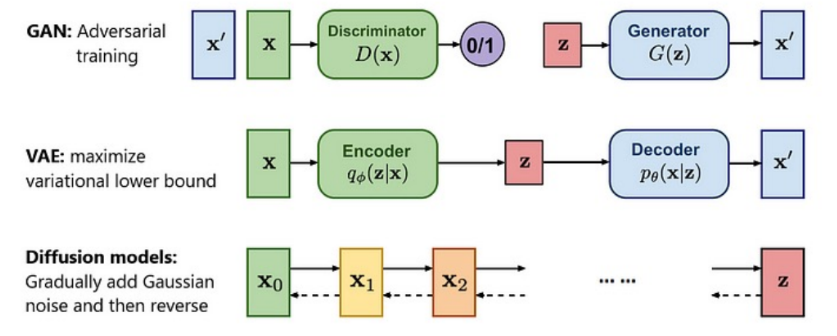
GAN + Imitation Learning Generative Adversarial Imitation Learning (GAIL)
- Sample trajectory from students
- Update the discriminator, which is aimed at classifying the teacher and the student
- Train the student policy which aims to minimize the discriminator’s accuracy
VAE + IL Action Chunking with Transformers
- Based on CVAE (conditional VAE)
- Encoder: expert action sequence + observation → latent
- Decoder: latent + more observation → action sequence prediction
- Key: action chunking + temporal ensemble
Diffusion + IL Diffusion Policy